
欢迎访问Python每天3分钟系列。
每天花3分钟时间,学习或温习一个Python知识点。

经过几天的考虑,我决定从每天更新改成每周5次更新。这个频率不再改变,至少更新到第199篇。感谢大家的支持!
今天是第033篇:
批量合并不同文件夹内的多个csv文件
这是麦友@罗敬芳的留言:
“麦叔,希望学个知识:不同文件夹内的多个csv文件批量合并
这里面有三个知识点:
-
文件的基本操作:读文件,写文件 -
对文件夹的驾驭 -
csv库的使用
我给两个方案,一个简单方案,一个灵活方案。
为了支持简单方案,我们先做如下假设:
-
这些csv文件格式都是相同的。这个假设对灵活方案也是需要的。 -
有两个文件夹d1,d2,下面分别放着一个csv文件
目标是把这2个文件合并成一个csv文件。
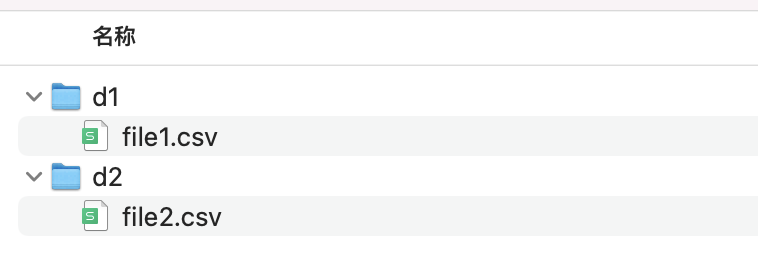
file1内容:
name,age,score
张三,12,98
李四,14,88
麦叔,15,99file2内容:
name,age,score
Tom,12,98
Jack,14,88
Marry,15,99简单实现
下面是一个简单的实现,文件夹和文件的名字都是写死的。虽然不是最好的方案,但对学习还是有帮助的:
import csv
# 打开结果文件,名为all.csv
with open('all.csv', 'w') as result:
# 把结果文件转成一个csv写入器对象
csv_writer = csv.writer(result)
# 打开第一个文件
with open('d1/file1.csv') as file:
# 把源文件转成一个csv读入器
csvreader = csv.reader(file)
# 循环读入每一行
for row in csvreader:
# 调用写入器写入一行
csv_writer.writerow(row)
# 打开第2个文件
with open('d2/file2.csv') as file:
csvreader = csv.reader(file)
# 跳过第一行,否则会出现重复的csv文件的头
next(csvreader)
for row in csvreader:
csv_writer.writerow(row)
print('合并后的结果:')
with open('all.csv') as result:
for row in result:
# 注意打印时加上end='',否则会出现多余的空行
print(row, end='')如果在Windows上,生成的csv文件也许会有多余的空行,这时候可以把下面的代码:
with open('all.csv', 'w') as result:改成:
with open('all.csv', 'w', newline='') as result:注意里面有段逻辑是防止文件header重复。
好一点的方案
下面这个方案要灵活多了。可以自己定义多个文件夹,还可以支持文件夹下任意数量的csv文件:
import csv
from os import listdir
# 目录列表
dirs = ['d1', 'd2']
# 打开结果文件
with open('all.csv', 'w') as result:
# 把结果文件转成一个csv写入器对象
csv_writer = csv.writer(result)
# 判定是否已经添加了header行
is_header_added = False
# 循环目录
for dir in dirs:
# 循环目录中所有的文件
for filename in listdir(dir):
# 找到csv文件
if filename.endswith('.csv'):
with open(f'{dir}/{filename}') as file:
csvreader = csv.reader(file)
# 读取文件的header行
header = next(csvreader)
# 目标文件只添加一次header
if not is_header_added:
csv_writer.writerow(header)
is_header_added = True
# 添加数据行
for row in csvreader:
csv_writer.writerow(row)
print('合并后的结果:')
with open('all.csv') as result:
for row in result:
# 注意打印时加上end='',否则会出现多余的空行
print(row, end='')注释写的还算清楚,这里就不多说了。
这个方案应该算比较灵活了,例子中是用的相对路径,假设目录就在当前运行Python的目录下。如果把目录改成绝对路径应该也是可以的。
今天大大超过3分钟了,就说到这里,有问题给我留言。
最近更新:
声明:本网站资源来源于网络收集,如有侵权,请联系站长进行删除处理。 分享目的仅供大家学习和交流,请不要用于商业用途,否则后果自负。本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解。本站资源售价只是赞助,收取费用仅维持本站的日常运营所需。反馈邮箱:1159995880@qq.com
评论(0)